파티션에 대해 공부하기 전에, 카프카에서 사용되는 몇 가지 개념과 그것들이 파티션과 어떻게 연관이 있는지를 알아보자.
Events
이벤트란, 과거에 일어난 사실을 뜻한다. 이벤트는 발생함으로 인해 변화된 상태를 가지고 시스템 사이를 오가는, 불변하는 데이터이다.
Streams
이벤트 스트림이란, 관련된 이벤트들을 뜻한다.
Topics
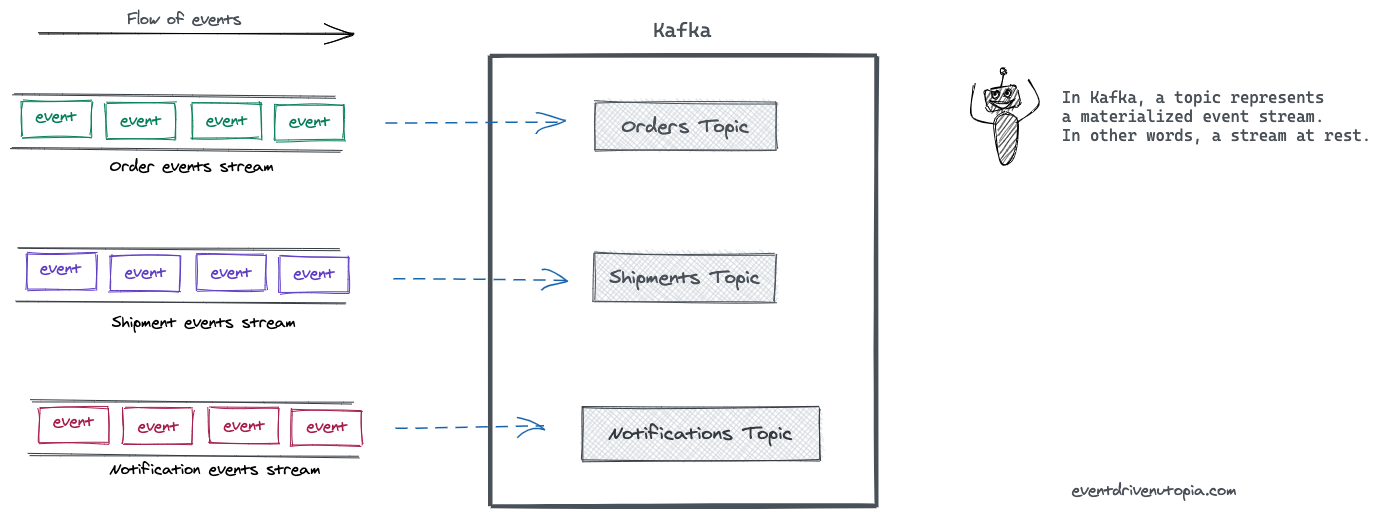
이벤트 스트림이 카프카에서는 토픽이란 이름으로 저장된다. 카프카의 세계에서는 토픽이 구체화된 이벤트 스트림을 뜻한다. 토픽은 연관된 이벤트들을 묶어 영속화하는데, 이는 데이터베이스의 테이블이나 파일 시스템의 폴더들에 비유할 수 있다.
토픽은 카프카에서 Producer 와 Consumer 를 분리하는 중요한 컨셉이다. Producer 는 카프카의 토픽에 메시지를 저장 (Push) 하고 Consumer 는 저장된 메시지를 읽어 (Pull) 온다. 하나의 토픽에 여러 Producer / Consumer 가 존재할 수 있다.
위의 개념들은 아래의 그림으로도 설명이 가능하다. Event 가 관련된 것들끼리 모여 Stream 을 이루게 되고, 이것이 카프카에 저장될 때 Topic 의 이름으로 저장된다.
Partitions
이제 본격적으로, 파티션에 대한 내용을 다루려 한다. 위에서 설명한 카프카의 토픽들은 여러 파티션으로 나눠진다. 토픽이 카프카에서 일종의 논리적인 개념이라면, 파티션은 토픽에 속한 레코드를 실제 저장소에 저장하는 가장 작은 단위이다. 각각의 파티션은 Append-Only 방식으로 기록되는 하나의 로그 파일이다.

참고한 포스팅에서 Record 와 Message 는 위의 그림에서 표현하는 것과 같이 파티션 내에 저장되는 메시지라는 의미로 사용되었다.
Offsets and the ordering of messages
파티션의 레코드는 각각이 Offset 이라 불리는, 파티션 내에서 고유한 레코드의 순서를 의미하는 식별자 정보를 가진다. 하지만 카프카는 일반적으로 메시지의 순서를 보장하지 않는다. 위에서 각각의 파티션은 Append-Only 방식으로 레코드를 기록한다 했고, 내부적으로 Offset 이라는 정보를 사용하는데 왜 메시지의 순서가 보장되지 않는 것일까? 자세한 내용은 아래의 내용을 보면 이해할 수 있고, 간단하게는 파티션 간에는 순서가 보장되지 않으므로 결국 메시지의 순서가 보장되지 않는다 할 수 있다.
Offset 정보는 카프카에 의해서 관리되고, 값이 계속 증가하며 불변하는 숫자 정보이다. 레코드가 파티션에 쓰여질 때 항상 기록의 맨 뒤에 쓰여지고, 다음 순서의 Offset 값을 갖게 된다. 오프셋은 파티션에서 레코드를 읽고 사용하는 Consumer 에게 특히 유용한데, 자세한 내용은 뒤에서 설명하겠다.
아래의 그림은 세 개의 파티션을 갖는 토픽을 보여준다. 레코드는 각 파티션의 마지막에 추가된다. 아래에서 볼 수 있듯, 메시지는 파티션 내에서는 유의미한 순서를 가지고 이를 보장하지만, 파티션 간에는 보장되지 않는다.

Partitions are the way that Kafka provides Scalability
카프카의 클러스터는 브로커라 불리는 하나 혹은 그 이상의 서버들로 이루어지는데, 각각의 브로커는 전체 클러스터에 속한 레코드의 서브셋을 가진다.
카프카는 토픽의 파티션들을 여러 브로커에 배포하는데 이로 인해 얻을 수 있는 다음과 같은 이점들이 있다.
- 만약 카프카가 한 토픽의 모든 파티션을 하나의 브로커에 넣을 경우, 해당 토픽의 확장성은 브로커의 I/O 처리량에 의해 제약된다. 파티션들을 여러 브로커에 나눔으로써, 하나의 토픽은 수평적으로 확장될 수 있고 이로 인해 브로커의 처리 능력보다 더 큰 성능을 제공할 수 있게 된다.
- 토픽은 여러 Consumer 에 의해 동시에 처리될 수 있다. 단일 브로커에서 모든 파티션을 제공하면 지원할 수 있는 Consumer 수가 제약되는데, 여러 브로커에서 파티션을 나누어 제공함으로써 더 많은 Consumer 들이 동시에 토픽의 메시지를 처리할 수 있게 된다.
- 동일한 Consumer 의 여러 인스턴스가 서로 다른 브로커에 있는 파티션에 접속함으로써 매우 높은 메시지 처리량을 가능케 한다. 각 Consumer 인스턴스는 하나의 파티션에서 메시지를 제공받고, 각각의 레코드는 명확한 처리 담당자가 존재함을 보장할 수 있다.
Partitions are the way that Kafka provides Redundancy
카프카는 여러 브로커에 동일 파티션의 복사본을 두 개 이상 유지한다. 이러한 복사본을 Replica 라 하는데, 브로커에 장애가 발생했을 때에도 장애가 발생한 브로커가 소유한 파티션의 복사본을 통해 컨슈머에게 지속적으로 메시지를 제공할 수 있게 한다.
파티션 복제는 다소 복잡해, 지금은 파티션에 대한 정리에 집중하고 다음 포스팅에서 Replica 를 주제로 다시 정리하려 한다.
Writing Records to Partitions
위에서 파티션이 무엇인지, 어떤 방식으로 사용되고 어떤 장점을 갖는지를 정리해 봤다. 그러면 파티션에 레코드를 어떻게 작성하고 어떻게 읽을까? 우선 레코드의 작성법부터 살펴보자. Producer 는 각각의 레코드가 어떤 파티션에 쓰여질 것인지를 어떻게 결정할까? 다음과 같이 세 가지의 방법이 존재한다.
Using a Partition Key
Producer 는 파티션 키를 사용해서 특정한 파티션에 메시지를 전달할 수 있다. 파티션 키는 Application Context 에서 파생될 수 있는 어떤 값이든 될 수 있다. 고유한 장비의 ID 나 사용자의 ID 는 좋은 파티션 키를 만들 수 있다.
기본적으로 파티션 키는 해싱 함수를 통해 전달되고 해싱 함수는 동일한 키를 갖는 모든 레코드들이 동일한 파티션에 도착하는 것을 보장한다. 파티션 키를 지정할 경우 다음 그림과 같이 관련된 이벤트를 동일한 파티션에 유지함으로써 전달된 순서가 그대로 유지되는 것을 보장할 수 있다.
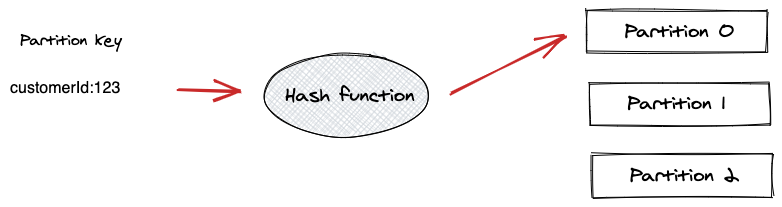
파티션 키를 사용한 방법이 위와 같이 발생한 이벤트의 순서를 보장할 수 있다는 장점을 가진 반면, 키가 제대로 분산되지 않는 경우 특정 브로커만 메시지를 받는 단점도 존재한다.
예를 들어, 고객의 ID 가 파티션 키로 사용되고 어떤 고객이 트래픽의 90% 를 생성한다 하자. 이 경우, 대부분의 어플리케이션 수행 동안 하나의 파티션에서 90% 의 트래픽을 감당하게 된다. 전체 트래픽이 작은 경우는 이를 무시할 수 있지만, 만약 트래픽이 많은 경우에 이와 같은 상황이 발생한다면 이는 종종 브로커의 장애로 이어질 수 있다.
이런 이유로, 파티션 키를 사용하고자 한다면 이들이 잘 분산되는 지를 확인할 필요가 있다.
Allowing Kafka to decide the partition
Producer 가 레코드를 생성할 때 파티션 키를 명시하지 않으면, Kafka 는 Round-Robin 방식을 사용해 파티션을 배정한다. 이러한 레코드들은 해당 토픽의 파티션들에 고루 분배된다.
그러나, 파티션 키가 사용되지 않을 경우 레코드들의 순서는 보장되지 않는다. 위에서 파티션 키를 사용할 경우와 반대로, 순서가 보장되지 않는 대신 파티션의 분배는 고루 이루어진다.
Writing a customer partitioner
특정 상황에서는, Producer 가 서로 다른 비즈니스 규칙을 사용한 자체 파티셔너 구현을 사용할 수도 있다.
Reading records from partitions
Producer 가 레코드 생성할 때 어떤 파티션에 이를 저장할 지를 위에서 봤으니, 이제는 Consumer 가 파티션에서 레코드를 어떻게 읽는 지를 알아볼 차례이다.
보통의 pub/sub 모델과는 달리, Kafka 는 메시지를 Consumer 에 전달 (push) 하지 않는다. 대신, Consumer 가 카프카의 파티션으로부터 메시지를 읽어 (pull) 가야 한다. 컨슈머는 브로커의 파티션과 연결해, 메시지들이 쓰여진 순서대로 메시지를 읽는다.
메시지의 Offset 은 Consumer 측의 커서와 같이 동작한다. Consumer 는 메시지의 오프셋을 추적하고 이를 통해 이미 소비한 메시지를 저장한다. 메시지를 읽고 난 뒤 Consumer 는 파티션의 다음 Offset 으로 커서를 이동하고, 다시 메시지를 읽고, .. 이 과정을 계속 반복한다.
각 파티션에서 마지막으로 소비된 메시지의 Offset 을 기억함으로써 Consumer 는 어떤 시점에 파티션의 어떤 위치에서 재시작할 수 있다. 이를 통해 Consumer 는 장애를 복구한 뒤 메시지 소비를 재시작할 수 있다.

파티션은 하나 혹은 그 이상의 Consumer 들로부터 소비될 수 있고, 각각은 서로 다른 Offset 을 가지고 메시지를 읽을 수 있다. 카프카는 Consumer Group 이라는 개념을 사용하는데, 이는 어떤 토픽을 소비하는 Consumer 들을 그룹으로 묶은 것이다. 동일한 Consumer Group 에 있는 Consumer 들은 동일한 Group-Id 를 부여받는다. 파티션 내의 메시지는 그룹 내의 Consumer 중 하나에 의해서만 소비되는 것을 보장한다.
아래의 그림은 Consumer 그룹 내에서 파티션들이 어떻게 소비되는 지를 보여준다.
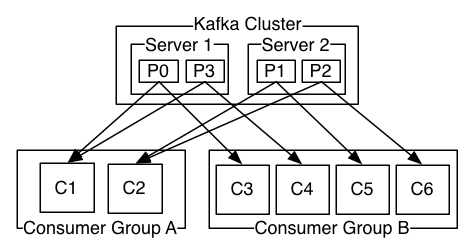
Consumer Group 은 Consumer 들이 병렬적으로 메시지를 소비할 수 있도록 한다. 병렬 처리를 가능케 함으로써 처리량은 매우 높아지지만, 그룹의 Maximum Parallelism 은 토픽의 파티션 개수와 동일하다.
예를 들어, N 개의 파티션이 존재하는 토픽에 N + 1 개의 Consumer 가 있는 경우, N 개의 Consumer 들은 파티션을 각각 배정받지만 남은 Consumer 는 다른 Consumer 가 장애가 발생하지 않는 한, Idle 상태로 파티션에 배정되기를 기다리게 된다. 이는 Hot Failover 를 구현하는 좋은 전략이 될 수 있다.
아래의 그림은 위의 예시를 표현한 것이다.
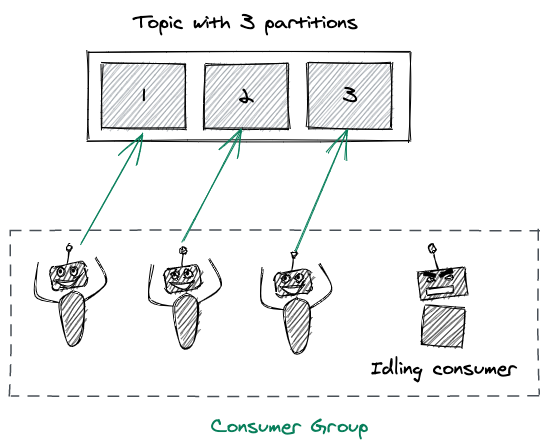
여기서 중요한 것은, Consumer 의 개수가 토픽의 병렬성 정도를 결정하지 않고, 결정하는 것은 파티션의 개수라는 것이다. 하지만 파티션을 늘리는 것이 항상 장점으로 작용하지는 않는다. 파티션의 개수에 따른 이점과 문제점은 추후에 다시 정리해보도록 하겠다.
# Reference.
'Middleware > Message Queue' 카테고리의 다른 글
| Kafka 설정 - 포인트만 (0) | 2022.04.24 |
|---|---|
| Spring Boot를 이용한 Kafka Pub Sub 개발 (0) | 2021.08.31 |
| Spring Boot에서 Apache Kafka 사용 ... 2/2 (0) | 2021.08.10 |
| Spring Boot에서 Apache Kafka 사용 ... 1/2 (0) | 2021.08.10 |
| 윈도우에서 Apache Kafka 개발 환경 만들기 (0) | 2021.08.10 |