Application Modernization/Container & PaaS
K8S HPA(Horizontal Pod Autoscaling) 적용
Cloud Applicaiton Architect
2022. 4. 25. 13:54
반응형
개요
HPA(Horizontal Pod Autoscaling)는 K8S 노드 내부의 Pod의 레플리카 확장을 의미한다. CPU 사용량에 따라 배포된 파드의 복제를 지정해 서비스가 원활하게 작동할 수 있도록 하는데 그 목표가 있다.(이는 추후에 설명할 워크노드의 인스턴스를 늘리는 Instance Autoscaling 과는 다르다.)
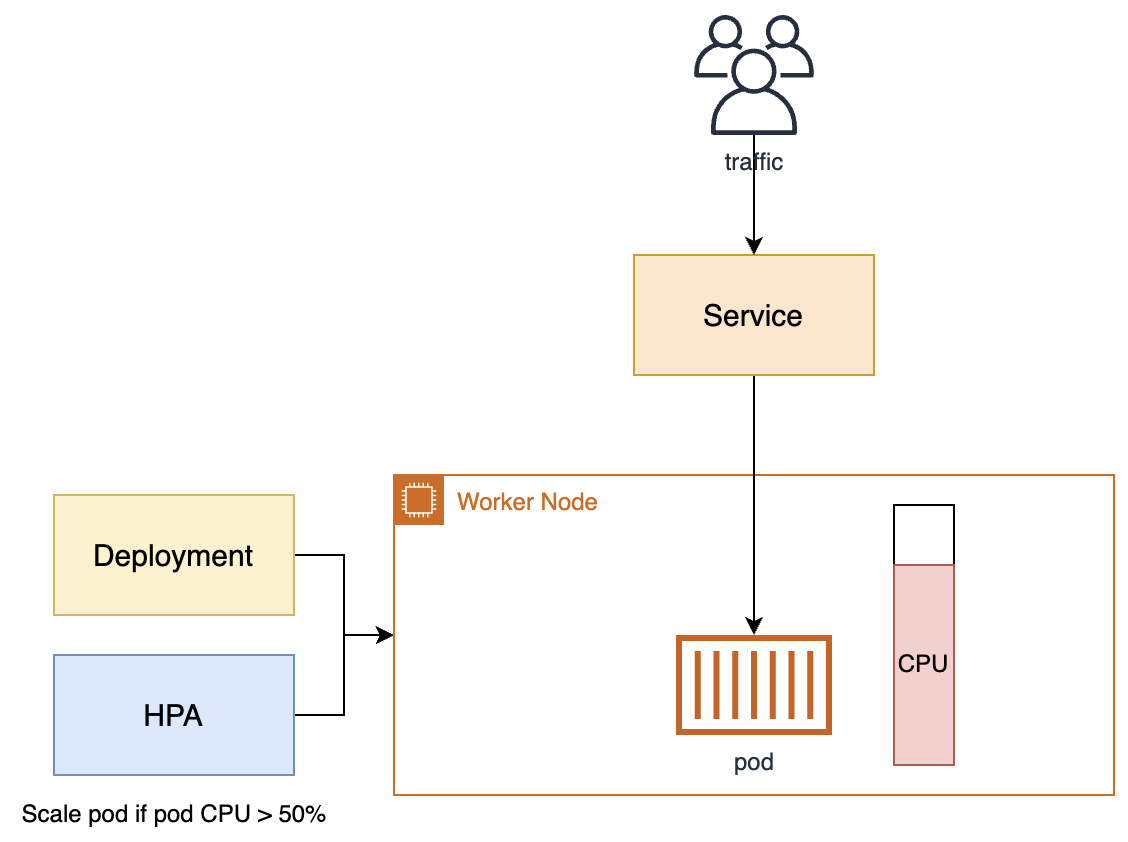
적용 순서(AWS EKS 기준)
1. 쿠버네티스 metrics server를 생성한다. Metrics Server는 쿠버네티스 클러스터 전체의 리소스 사용 데이터를 집계한다. 각 워커 노드에 설치된 kubelet을 통해서 워커 노드나 컨테이너의 CPU 및 메모리 사용량 같은 메트릭을 수집한다.
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml설치가 완료되었으면 아래의 명령어로 정상 설치여부를 확인
kubectl get deployment metrics-server -n kube-system
2. HPA를 사용하고자 하는 pod의 replica를 생성한다. 여기서는 기본 값으로 1개 생성. deployment.yaml을 아래를 보고 참조한다.
deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: #[deployment 이름 e.g. demo-flask-backend]
namespace: default
spec:
replicas: 1 #[복재 개수]
selector:
matchLabels:
app: #[lable명 이름 e.g. demo-flask-backend]
template:
metadata:
labels:
app: #[tempalte 이름 e.g. demo-flask-backend]
spec:
containers:
- name: #[배포할 컨테이너 이름이름 e.g. demo-flask-backend]
image: #[배포할 이미지 ECR]
imagePullPolicy: Always
ports:
- containerPort: #[배포할 Pod Port]
resources:
requests:
cpu: 250m
limits:
cpu: 500m
EOFkubectl apply -f deployment.yaml3. HPA 생성 및 적용
cat <<EOF> flask-hpa.yaml
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: [#생성할 hpa이름 e.g. demo-flask-backend-hpa]
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: [# 사용할 deplopyment 이름 e.g. demo-flask-backend]
minReplicas: 1
maxReplicas: 5
targetCPUUtilizationPercentage: 30
EOFkubectl apply -f flask-hpa.yaml4. 상태 확인
kubectl get hpa -w
kubectl get hpa -w
Apache AD, Locust, J-Meta 등 익숙한 스트레스 툴을 이용해 배포한 어플리케이션을 호출 해 보면 설정한 CPU 임계치를 초과할 경우 POD Replica가 진행되는 것을 확인 할 수 있다.
5. 삭제 시
kubectl delete hpa --all
kubectl delete hpa --all
반응형